第二章:資料模型與查詢語言
語言的邊界就是思想的邊界。
—— 路德維奇・維特根斯坦,《邏輯哲學》(1922)
[TOC]
資料模型可能是軟體開發中最重要的部分了,因為它們的影響如此深遠:不僅僅影響著軟體的編寫方式,而且影響著我們的 解題思路。
多數應用使用層層疊加的資料模型構建。對於每層資料模型的關鍵問題是:它是如何用低一層資料模型來 表示 的?例如:
- 作為一名應用開發人員,你觀察現實世界(裡面有人員、組織、貨物、行為、資金流向、感測器等),並採用物件或資料結構,以及操控那些資料結構的 API 來進行建模。那些結構通常是特定於應用程式的。
- 當要儲存那些資料結構時,你可以利用通用資料模型來表示它們,如 JSON 或 XML 文件、關係資料庫中的表或圖模型。
- 資料庫軟體的工程師選定如何以記憶體、磁碟或網路上的位元組來表示 JSON / XML/ 關係 / 圖資料。這類表示形式使資料有可能以各種方式來查詢,搜尋,操縱和處理。
- 在更低的層次上,硬體工程師已經想出了使用電流、光脈衝、磁場或者其他東西來表示位元組的方法。
一個複雜的應用程式可能會有更多的中間層次,比如基於 API 的 API,不過基本思想仍然是一樣的:每個層都透過提供一個明確的資料模型來隱藏更低層次中的複雜性。這些抽象允許不同的人群有效地協作(例如資料庫廠商的工程師和使用資料庫的應用程式開發人員)。
資料模型種類繁多,每個資料模型都帶有如何使用的設想。有些用法很容易,有些則不支援如此;有些操作執行很快,有些則表現很差;有些資料轉換非常自然,有些則很麻煩。
掌握一個數據模型需要花費很多精力(想想關係資料建模有多少本書)。即便只使用一個數據模型,不用操心其內部工作機制,構建軟體也是非常困難的。然而,因為資料模型對上層軟體的功能(能做什麼,不能做什麼)有著至深的影響,所以選擇一個適合的資料模型是非常重要的。
在本章中,我們將研究一系列用於資料儲存和查詢的通用資料模型(前面列表中的第 2 點)。特別地,我們將比較關係模型,文件模型和少量基於圖形的資料模型。我們還將檢視各種查詢語言並比較它們的用例。在 第三章 中,我們將討論儲存引擎是如何工作的。也就是說,這些資料模型實際上是如何實現的(列表中的第 3 點)。
關係模型與文件模型
現在最著名的資料模型可能是 SQL。它基於 Edgar Codd 在 1970 年提出的關係模型【1】:資料被組織成 關係(SQL 中稱作 表),其中每個關係是 元組(SQL 中稱作 行) 的無序集合。
關係模型曾是一個理論性的提議,當時很多人都懷疑是否能夠有效實現它。然而到了 20 世紀 80 年代中期,關係資料庫管理系統(RDBMSes)和 SQL 已成為大多數人們儲存和查詢某些常規結構的資料的首選工具。關係資料庫已經持續稱霸了大約 25~30 年 —— 這對計算機史來說是極其漫長的時間。
關係資料庫起源於商業資料處理,在 20 世紀 60 年代和 70 年代用大型計算機來執行。從今天的角度來看,那些用例顯得很平常:典型的 事務處理(將銷售或銀行交易,航空公司預訂,庫存管理資訊記錄在庫)和 批處理(客戶發票,工資單,報告)。
當時的其他資料庫迫使應用程式開發人員必須考慮資料庫內部的資料表示形式。關係模型致力於將上述實現細節隱藏在更簡潔的介面之後。
多年來,在資料儲存和查詢方面存在著許多相互競爭的方法。在 20 世紀 70 年代和 80 年代初,網狀模型(network model)和層次模型(hierarchical model)曾是主要的選擇,但關係模型(relational model)隨後佔據了主導地位。物件資料庫在 20 世紀 80 年代末和 90 年代初來了又去。XML 資料庫在二十一世紀初出現,但只有小眾採用過。關係模型的每個競爭者都在其時代產生了大量的炒作,但從來沒有持續【2】。
隨著電腦越來越強大和互聯,它們開始用於日益多樣化的目的。關係資料庫非常成功地被推廣到業務資料處理的原始範圍之外更為廣泛的用例上。你今天在網上看到的大部分內容依舊是由關係資料庫來提供支援,無論是線上釋出,討論,社交網路,電子商務,遊戲,軟體即服務生產力應用程式等等內容。
NoSQL 的誕生
現在 - 2010 年代,NoSQL 開始了最新一輪嘗試,試圖推翻關係模型的統治地位。“NoSQL” 這個名字讓人遺憾,因為實際上它並沒有涉及到任何特定的技術。最初它只是作為一個醒目的 Twitter 標籤,用在 2009 年一個關於分散式,非關係資料庫上的開源聚會上。無論如何,這個術語觸動了某些神經,並迅速在網路創業社群內外傳播開來。好些有趣的資料庫系統現在都與 #NoSQL 標籤相關聯,並且 NoSQL 被追溯性地重新解釋為 不僅是 SQL(Not Only SQL) 【4】。
採用 NoSQL 資料庫的背後有幾個驅動因素,其中包括:
- 需要比關係資料庫更好的可伸縮性,包括非常大的資料集或非常高的寫入吞吐量
- 相比商業資料庫產品,免費和開源軟體更受偏愛
- 關係模型不能很好地支援一些特殊的查詢操作
- 受挫於關係模型的限制性,渴望一種更具多動態性與表現力的資料模型【5】
不同的應用程式有不同的需求,一個用例的最佳技術選擇可能不同於另一個用例的最佳技術選擇。因此,在可預見的未來,關係資料庫似乎可能會繼續與各種非關係資料庫一起使用 - 這種想法有時也被稱為 混合持久化(polyglot persistence)。
物件關係不匹配
目前大多數應用程式開發都使用面向物件的程式語言來開發,這導致了對 SQL 資料模型的普遍批評:如果資料儲存在關係表中,那麼需要一個笨拙的轉換層,處於應用程式程式碼中的物件和表,行,列的資料庫模型之間。模型之間的不連貫有時被稱為 阻抗不匹配(impedance mismatch)^i。
像 ActiveRecord 和 Hibernate 這樣的 物件關係對映(ORM object-relational mapping) 框架可以減少這個轉換層所需的樣板程式碼的數量,但是它們不能完全隱藏這兩個模型之間的差異。
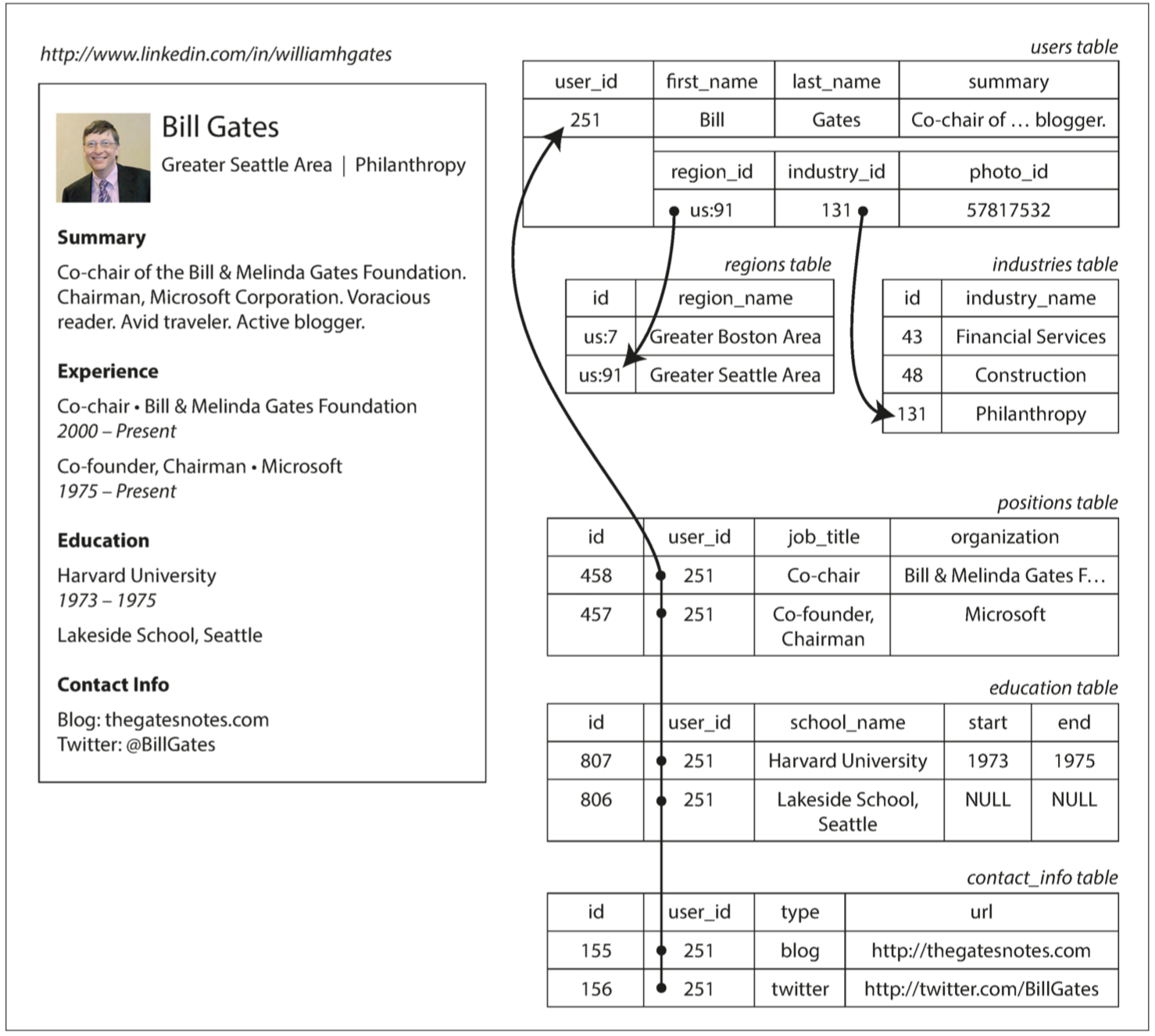
圖 2-1 使用關係型模式來表示領英簡介
例如,圖 2-1 展示瞭如何在關係模式中表示簡歷(一個 LinkedIn 簡介)。整個簡介可以透過一個唯一的識別符號 user_id 來標識。像 first_name 和 last_name 這樣的欄位每個使用者只出現一次,所以可以在 User 表上將其建模為列。但是,大多數人在職業生涯中擁有多於一份的工作,人們可能有不同樣的教育階段和任意數量的聯絡資訊。從使用者到這些專案之間存在一對多的關係,可以用多種方式來表示:
{kind=link}
- 傳統 SQL 模型(SQL:1999 之前)中,最常見的規範化表示形式是將職位,教育和聯絡資訊放在單獨的表中,對 User 表提供外來鍵引用,如 圖 2-1 所示。
- 後續的 SQL 標準增加了對結構化資料型別和 XML 資料的支援;這允許將多值資料儲存在單行內,並支援在這些文件內查詢和索引。這些功能在 Oracle,IBM DB2,MS SQL Server 和 PostgreSQL 中都有不同程度的支援【6,7】。JSON 資料型別也得到多個數據庫的支援,包括 IBM DB2,MySQL 和 PostgreSQL 【8】。
- 第三種選擇是將職業,教育和聯絡資訊編碼為 JSON 或 XML 文件,將其儲存在資料庫的文字列中,並讓應用程式解析其結構和內容。這種配置下,通常不能使用資料庫來查詢該編碼列中的值。
對於一個像簡歷這樣自包含文件的資料結構而言,JSON 表示是非常合適的:請參閱 例 2-1。JSON 比 XML 更簡單。面向文件的資料庫(如 MongoDB 【9】,RethinkDB 【10】,CouchDB 【11】和 Espresso【12】)支援這種資料模型。
例 2-1. 用 JSON 文件表示一個 LinkedIn 簡介
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{
"job_title": "Co-chair",
"organization": "Bill & Melinda Gates Foundation"
},
{
"job_title": "Co-founder, Chairman",
"organization": "Microsoft"
}
],
"education": [
{
"school_name": "Harvard University",
"start": 1973,
"end": 1975
},
{
"school_name": "Lakeside School, Seattle",
"start": null,
"end": null
}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}有一些開發人員認為 JSON 模型減少了應用程式程式碼和儲存層之間的阻抗不匹配。不過,正如我們將在 第四章 中看到的那樣,JSON 作為資料編碼格式也存在問題。缺乏一個模式往往被認為是一個優勢;我們將在 “文件模型中的模式靈活性” 中討論這個問題。
JSON 表示比 圖 2-1 中的多表模式具有更好的 區域性性(locality)。如果在前面的關係型示例中獲取簡介,那需要執行多個查詢(透過 user_id 查詢每個表),或者在 User 表與其下屬表之間混亂地執行多路連線。而在 JSON 表示中,所有相關資訊都在同一個地方,一個查詢就足夠了。
從使用者簡介檔案到使用者職位,教育歷史和聯絡資訊,這種一對多關係隱含了資料中的一個樹狀結構,而 JSON 表示使得這個樹狀結構變得明確(見 圖 2-2)。
{kind=link}
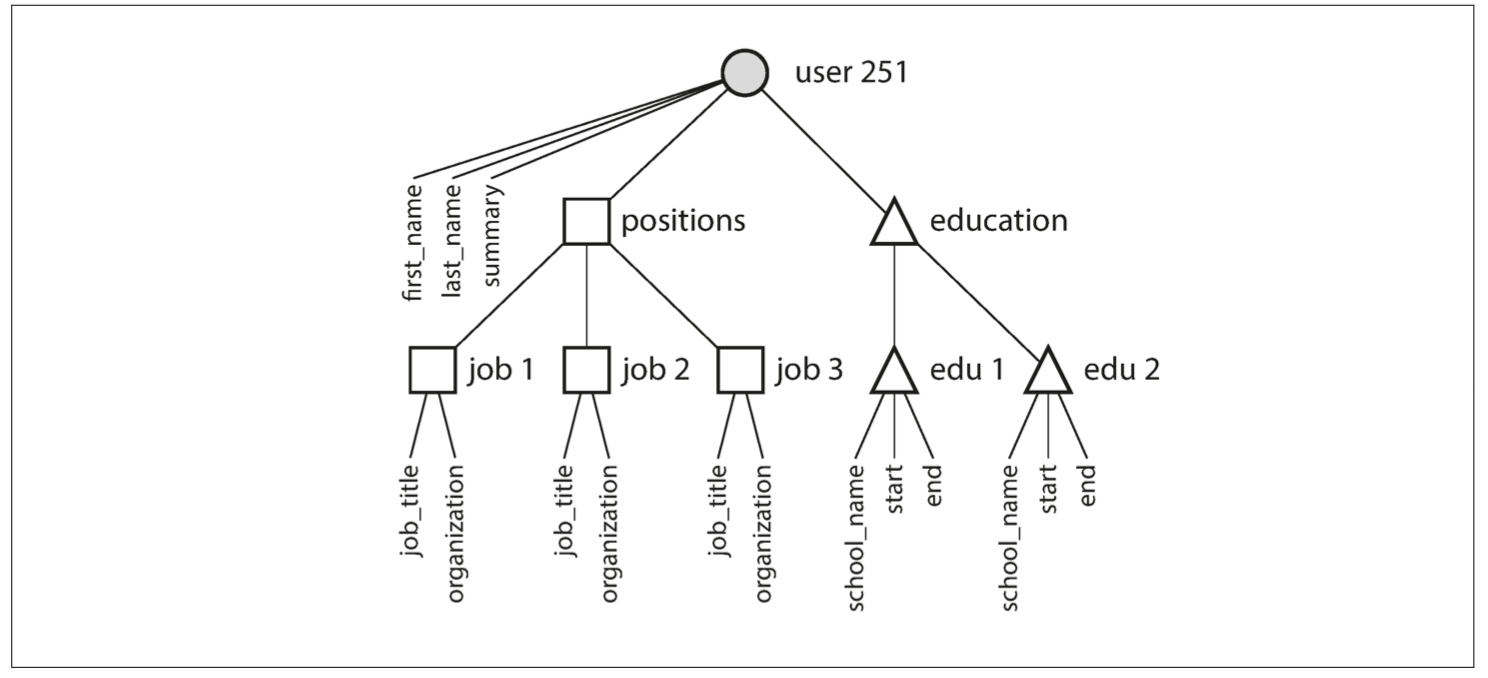
圖 2-2 一對多關係構建了一個樹結構
多對一和多對多的關係
在上一節的 例 2-1 中,region_id 和 industry_id 是以 ID,而不是純字串 “Greater Seattle Area” 和 “Philanthropy” 的形式給出的。為什麼?
如果使用者介面用一個自由文字欄位來輸入區域和行業,那麼將他們儲存為純文字字串是合理的。另一方式是給出地理區域和行業的標準化的列表,並讓使用者從下拉列表或自動填充器中進行選擇,其優勢如下:
- 各個簡介之間樣式和拼寫統一
- 避免歧義(例如,如果有幾個同名的城市)
- 易於更新 —— 名稱只儲存在一個地方,如果需要更改(例如,由於政治事件而改變城市名稱),很容易進行全面更新。
- 本地化支援 —— 當網站翻譯成其他語言時,標準化的列表可以被本地化,使得地區和行業可以使用使用者的語言來顯示
- 更好的搜尋 —— 例如,搜尋華盛頓州的慈善家就會匹配這份簡介,因為地區列表可以編碼記錄西雅圖在華盛頓這一事實(從 “Greater Seattle Area” 這個字串中看不出來)
儲存 ID 還是文字字串,這是個 副本(duplication) 問題。當使用 ID 時,對人類有意義的資訊(比如單詞:Philanthropy)只儲存在一處,所有引用它的地方使用 ID(ID 只在資料庫中有意義)。當直接儲存文字時,對人類有意義的資訊會複製在每處使用記錄中。
使用 ID 的好處是,ID 對人類沒有任何意義,因而永遠不需要改變:ID 可以保持不變,即使它標識的資訊發生變化。任何對人類有意義的東西都可能需要在將來某個時候改變 —— 如果這些資訊被複制,所有的冗餘副本都需要更新。這會導致寫入開銷,也存在不一致的風險(一些副本被更新了,還有些副本沒有被更新)。去除此類重複是資料庫 規範化(normalization) 的關鍵思想。[^ii]
[^ii]: 關於關係模型的文獻區分了幾種不同的規範形式,但這些區別幾乎沒有實際意義。一個經驗法則是,如果重複儲存了可以儲存在一個地方的值,則模式就不是 規範化(normalized) 的。
資料庫管理員和開發人員喜歡爭論規範化和非規範化,讓我們暫時保留判斷吧。在本書的 第三部分,我們將回到這個話題,探討系統的方法用以處理快取,非規範化和衍生資料。
不幸的是,對這些資料進行規範化需要多對一的關係(許多人生活在一個特定的地區,許多人在一個特定的行業工作),這與文件模型不太吻合。在關係資料庫中,透過 ID 來引用其他表中的行是正常的,因為連線很容易。在文件資料庫中,一對多樹結構沒有必要用連線,對連線的支援通常很弱 [^iii]。
[^iii]: 在撰寫本文時,RethinkDB 支援連線,MongoDB 不支援連線,而 CouchDB 只支援預先宣告的檢視。
如果資料庫本身不支援連線,則必須在應用程式程式碼中透過對資料庫進行多個查詢來模擬連線。(在這種情況中,地區和行業的列表可能很小,改動很少,應用程式可以簡單地將其儲存在記憶體中。不過,執行連線的工作從資料庫被轉移到應用程式程式碼上。
此外,即便應用程式的最初版本適合無連線的文件模型,隨著功能新增到應用程式中,資料會變得更加互聯。例如,考慮一下對簡歷例子進行的一些修改:
組織和學校作為實體
在前面的描述中,
organization(使用者工作的公司)和school_name(他們學習的地方)只是字串。也許他們應該是對實體的引用呢?然後,每個組織、學校或大學都可以擁有自己的網頁(標識,新聞提要等)。每個簡歷可以連結到它所提到的組織和學校,並且包括他們的圖示和其他資訊(請參閱 圖 2-3,來自 LinkedIn 的一個例子)。推薦
假設你想新增一個新的功能:一個使用者可以為另一個使用者寫一個推薦。在使用者的簡歷上顯示推薦,並附上推薦使用者的姓名和照片。如果推薦人更新他們的照片,那他們寫的任何推薦都需要顯示新的照片。因此,推薦應該擁有作者個人簡介的引用。
{kind=link}

圖 2-3 公司名不僅是字串,還是一個指向公司實體的連結(LinkedIn 截圖)
圖 2-4 闡明瞭這些新功能需要如何使用多對多關係。每個虛線矩形內的資料可以分組成一個文件,但是對單位,學校和其他使用者的引用需要表示成引用,並且在查詢時需要連線。
{kind=link}
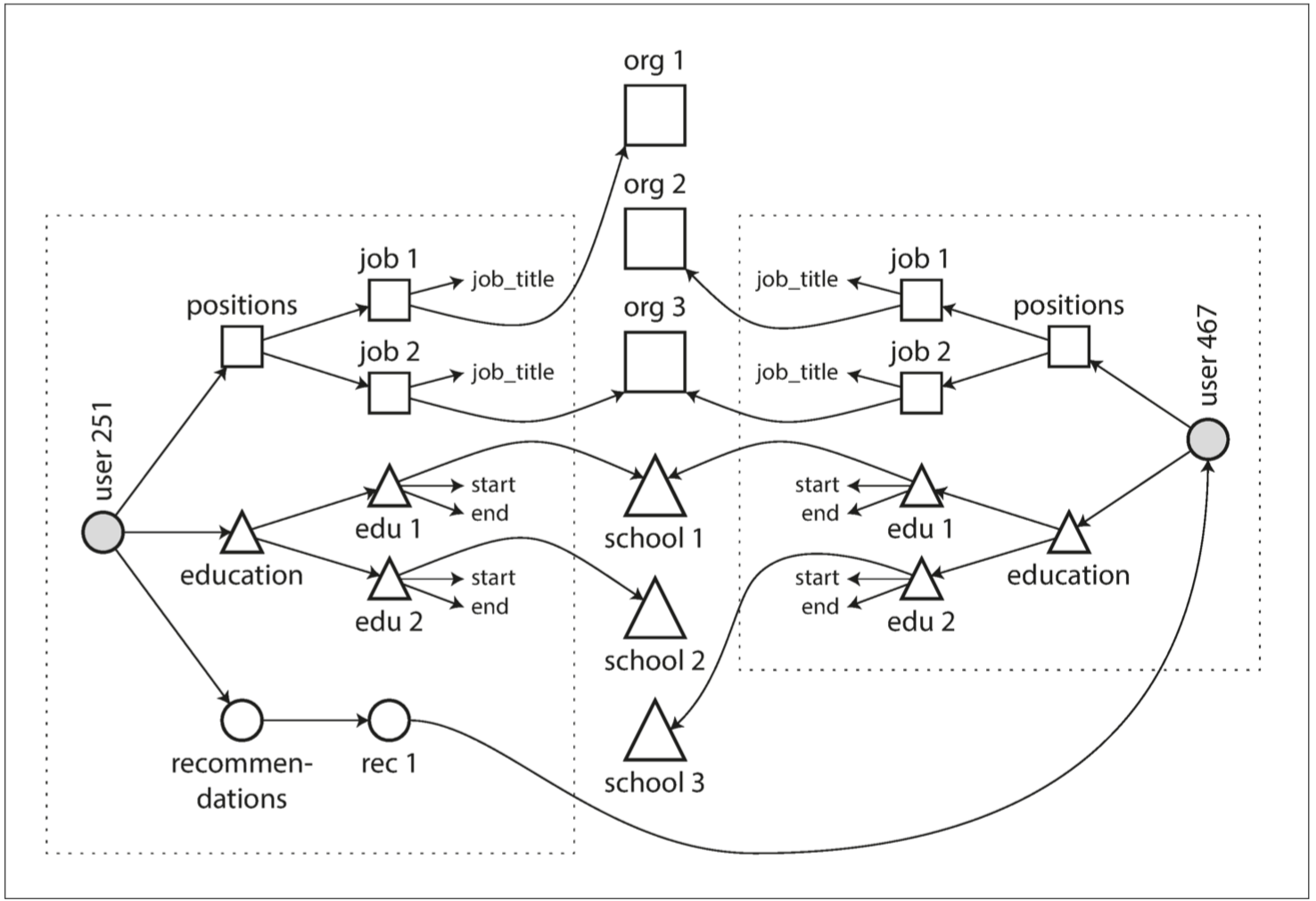
圖 2-4 使用多對多關係擴充套件簡歷
文件資料庫是否在重蹈覆轍?
在多對多的關係和連線已常規用在關係資料庫時,文件資料庫和 NoSQL 重啟了辯論:如何以最佳方式在資料庫中表示多對多關係。那場辯論可比 NoSQL 古老得多,事實上,最早可以追溯到計算機化資料庫系統。
20 世紀 70 年代最受歡迎的業務資料處理資料庫是 IBM 的資訊管理系統(IMS),最初是為了阿波羅太空計劃的庫存管理而開發的,並於 1968 年有了首次商業釋出【13】。目前它仍在使用和維護,執行在 IBM 大型機的 OS/390 上【14】。
IMS 的設計中使用了一個相當簡單的資料模型,稱為 層次模型(hierarchical model),它與文件資料庫使用的 JSON 模型有一些驚人的相似之處【2】。它將所有資料表示為巢狀在記錄中的記錄樹,這很像 圖 2-2 的 JSON 結構。
同文檔資料庫一樣,IMS 能良好處理一對多的關係,但是很難應對多對多的關係,並且不支援連線。開發人員必須決定是否複製(非規範化)資料或手動解決從一個記錄到另一個記錄的引用。這些二十世紀六七十年代的問題與現在開發人員遇到的文件資料庫問題非常相似【15】。
那時人們提出了各種不同的解決方案來解決層次模型的侷限性。其中最突出的兩個是 關係模型(relational model,它變成了 SQL,並統治了世界)和 網狀模型(network model,最初很受關注,但最終變得冷門)。這兩個陣營之間的 “大辯論” 在 70 年代持續了很久時間【2】。
那兩個模式解決的問題與當前的問題相關,因此值得簡要回顧一下那場辯論。
網狀模型
網狀模型由一個稱為資料系統語言會議(CODASYL)的委員會進行了標準化,並被數個不同的資料庫廠商實現;它也被稱為 CODASYL 模型【16】。
CODASYL 模型是層次模型的推廣。在層次模型的樹結構中,每條記錄只有一個父節點;在網路模式中,每條記錄可能有多個父節點。例如,“Greater Seattle Area” 地區可能是一條記錄,每個居住在該地區的使用者都可以與之相關聯。這允許對多對一和多對多的關係進行建模。
網狀模型中記錄之間的連結不是外來鍵,而更像程式語言中的指標(同時仍然儲存在磁碟上)。訪問記錄的唯一方法是跟隨從根記錄起沿這些鏈路所形成的路徑。這被稱為 訪問路徑(access path)。
最簡單的情況下,訪問路徑類似遍歷連結串列:從列表頭開始,每次檢視一條記錄,直到找到所需的記錄。但在多對多關係的情況中,數條不同的路徑可以到達相同的記錄,網狀模型的程式設計師必須跟蹤這些不同的訪問路徑。
CODASYL 中的查詢是透過利用遍歷記錄列和跟隨訪問路徑表在資料庫中移動遊標來執行的。如果記錄有多個父結點(即多個來自其他記錄的傳入指標),則應用程式程式碼必須跟蹤所有的各種關係。甚至 CODASYL 委員會成員也承認,這就像在 n 維資料空間中進行導航【17】。
儘管手動選擇訪問路徑能夠最有效地利用 20 世紀 70 年代非常有限的硬體功能(如磁帶驅動器,其搜尋速度非常慢),但這使得查詢和更新資料庫的程式碼變得複雜不靈活。無論是分層還是網狀模型,如果你沒有所需資料的路徑,就會陷入困境。你可以改變訪問路徑,但是必須瀏覽大量手寫資料庫查詢程式碼,並重寫來處理新的訪問路徑。更改應用程式的資料模型是很難的。
關係模型
相比之下,關係模型做的就是將所有的資料放在光天化日之下:一個 關係(表) 只是一個 元組(行) 的集合,僅此而已。如果你想讀取資料,它沒有迷宮似的巢狀結構,也沒有複雜的訪問路徑。你可以選中符合任意條件的行,讀取表中的任何或所有行。你可以透過指定某些列作為匹配關鍵字來讀取特定行。你可以在任何表中插入一個新的行,而不必擔心與其他表的外來鍵關係 [^iv]。
[^iv]: 外來鍵約束允許對修改進行限制,但對於關係模型這並不是必選項。即使有約束,外來鍵連線在查詢時執行,而在 CODASYL 中,連線在插入時高效完成。
在關係資料庫中,查詢最佳化器自動決定查詢的哪些部分以哪個順序執行,以及使用哪些索引。這些選擇實際上是 “訪問路徑”,但最大的區別在於它們是由查詢最佳化器自動生成的,而不是由程式設計師生成,所以我們很少需要考慮它們。
如果想按新的方式查詢資料,你可以宣告一個新的索引,查詢會自動使用最合適的那些索引。無需更改查詢來利用新的索引(請參閱 “資料查詢語言”)。關係模型因此使新增應用程式新功能變得更加容易。
關係資料庫的查詢最佳化器是複雜的,已耗費了多年的研究和開發精力【18】。關係模型的一個關鍵洞察是:只需構建一次查詢最佳化器,隨後使用該資料庫的所有應用程式都可以從中受益。如果你沒有查詢最佳化器的話,那麼為特定查詢手動編寫訪問路徑比編寫通用最佳化器更容易 —— 不過從長期看通用解決方案更好。
與文件資料庫相比
在一個方面,文件資料庫還原為層次模型:在其父記錄中儲存巢狀記錄(圖 2-1 中的一對多關係,如 positions,education 和 contact_info),而不是在單獨的表中。
但是,在表示多對一和多對多的關係時,關係資料庫和文件資料庫並沒有根本的不同:在這兩種情況下,相關專案都被一個唯一的識別符號引用,這個識別符號在關係模型中被稱為 外來鍵,在文件模型中稱為 文件引用【9】。該識別符號在讀取時透過連線或後續查詢來解析。迄今為止,文件資料庫沒有走 CODASYL 的老路。
關係型資料庫與文件資料庫在今日的對比
將關係資料庫與文件資料庫進行比較時,可以考慮許多方面的差異,包括它們的容錯屬性(請參閱 第五章)和處理併發性(請參閱 第七章)。本章將只關注資料模型中的差異。
支援文件資料模型的主要論據是架構靈活性,因區域性性而擁有更好的效能,以及對於某些應用程式而言更接近於應用程式使用的資料結構。關係模型透過為連線提供更好的支援以及支援多對一和多對多的關係來反擊。
哪種資料模型更有助於簡化應用程式碼?
如果應用程式中的資料具有類似文件的結構(即,一對多關係樹,通常一次性載入整個樹),那麼使用文件模型可能是一個好主意。將類似文件的結構分解成多個表(如 圖 2-1 中的 positions、education 和 contact_info)的關係技術可能導致繁瑣的模式和不必要的複雜的應用程式程式碼。
文件模型有一定的侷限性:例如,不能直接引用文件中的巢狀的專案,而是需要說 “使用者 251 的位置列表中的第二項”(很像層次模型中的訪問路徑)。但是,只要檔案巢狀不太深,這通常不是問題。
文件資料庫對連線的糟糕支援可能是個問題,也可能不是問題,這取決於應用程式。例如,如果某分析型應用程式使用一個文件資料庫來記錄何時何地發生了何事,那麼多對多關係可能永遠也用不上。【19】。
但如果你的應用程式確實會用到多對多關係,那麼文件模型就沒有那麼誘人了。儘管可以透過反規範化來消除對連線的需求,但這需要應用程式程式碼來做額外的工作以確保資料一致性。儘管應用程式程式碼可以透過向資料庫發出多個請求的方式來模擬連線,但這也將複雜性轉移到應用程式中,而且通常也會比由資料庫內的專用程式碼更慢。在這種情況下,使用文件模型可能會導致更複雜的應用程式碼與更差的效能【15】。
我們沒有辦法說哪種資料模型更有助於簡化應用程式碼,因為它取決於資料項之間的關係種類。對高度關聯的資料而言,文件模型是極其糟糕的,關係模型是可以接受的,而選用圖形模型(請參閱 “圖資料模型”)是最自然的。
文件模型中的模式靈活性
大多數文件資料庫以及關係資料庫中的 JSON 支援都不會強制文件中的資料採用何種模式。關係資料庫的 XML 支援通常帶有可選的模式驗證。沒有模式意味著可以將任意的鍵和值新增到文件中,並且當讀取時,客戶端無法保證文件可能包含的欄位。
文件資料庫有時稱為 無模式(schemaless),但這具有誤導性,因為讀取資料的程式碼通常假定某種結構 —— 即存在隱式模式,但不由資料庫強制執行【20】。一個更精確的術語是 讀時模式(即 schema-on-read,資料的結構是隱含的,只有在資料被讀取時才被解釋),相應的是 寫時模式(即 schema-on-write,傳統的關係資料庫方法中,模式明確,且資料庫確保所有的資料都符合其模式)【21】。
讀時模式類似於程式語言中的動態(執行時)型別檢查,而寫時模式類似於靜態(編譯時)型別檢查。就像靜態和動態型別檢查的相對優點具有很大的爭議性一樣【22】,資料庫中模式的強制性是一個具有爭議的話題,一般來說沒有正確或錯誤的答案。
在應用程式想要改變其資料格式的情況下,這些方法之間的區別尤其明顯。例如,假設你把每個使用者的全名儲存在一個欄位中,而現在想分別儲存名字和姓氏【23】。在文件資料庫中,只需開始寫入具有新欄位的新文件,並在應用程式中使用程式碼來處理讀取舊文件的情況。例如:
if (user && user.name && !user.first_name) {
// Documents written before Dec 8, 2013 don't have first_name
user.first_name = user.name.split(" ")[0];
}另一方面,在 “靜態型別” 資料庫模式中,通常會執行以下 遷移(migration) 操作:
ALTER TABLE users ADD COLUMN first_name text;
UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL
UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL模式變更的速度很慢,而且要求停運。它的這種壞名譽並不是完全應得的:大多數關係資料庫系統可在幾毫秒內執行 ALTER TABLE 語句。MySQL 是一個值得注意的例外,它執行 ALTER TABLE 時會複製整個表,這可能意味著在更改一個大型表時會花費幾分鐘甚至幾個小時的停機時間,儘管存在各種工具來解決這個限制【24,25,26】。
大型表上執行 UPDATE 語句在任何資料庫上都可能會很慢,因為每一行都需要重寫。要是不可接受的話,應用程式可以將 first_name 設定為預設值 NULL,並在讀取時再填充,就像使用文件資料庫一樣。
當由於某種原因(例如,資料是異構的)集合中的專案並不都具有相同的結構時,讀時模式更具優勢。例如,如果:
- 存在許多不同型別的物件,將每種型別的物件放在自己的表中是不現實的。
- 資料的結構由外部系統決定。你無法控制外部系統且它隨時可能變化。
在上述情況下,模式的壞處遠大於它的幫助,無模式文件可能是一個更加自然的資料模型。但是,要是所有記錄都具有相同的結構,那麼模式是記錄並強制這種結構的有效機制。第四章將更詳細地討論模式和模式演化。
查詢的資料區域性性
文件通常以單個連續字串形式進行儲存,編碼為 JSON、XML 或其二進位制變體(如 MongoDB 的 BSON)。如果應用程式經常需要訪問整個文件(例如,將其渲染至網頁),那麼儲存區域性性會帶來效能優勢。如果將資料分割到多個表中(如 圖 2-1 所示),則需要進行多次索引查詢才能將其全部檢索出來,這可能需要更多的磁碟查詢並花費更多的時間。
區域性性僅僅適用於同時需要文件絕大部分內容的情況。資料庫通常需要載入整個文件,即使只訪問其中的一小部分,這對於大型文件來說是很浪費的。更新文件時,通常需要整個重寫。只有不改變文件大小的修改才可以容易地原地執行。因此,通常建議保持相對小的文件,並避免增加文件大小的寫入【9】。這些效能限制大大減少了文件資料庫的實用場景。
值得指出的是,為了區域性性而分組集合相關資料的想法並不侷限於文件模型。例如,Google 的 Spanner 資料庫在關係資料模型中提供了同樣的區域性性屬性,允許模式宣告一個表的行應該交錯(巢狀)在父表內【27】。Oracle 類似地允許使用一個稱為 多表索引叢集表(multi-table index cluster tables) 的類似特性【28】。Bigtable 資料模型(用於 Cassandra 和 HBase)中的 列族(column-family) 概念與管理區域性性的目的類似【29】。
在 第三章 將還會看到更多關於區域性性的內容。
文件和關係資料庫的融合
自 2000 年代中期以來,大多數關係資料庫系統(MySQL 除外)都已支援 XML。這包括對 XML 文件進行本地修改的功能,以及在 XML 文件中進行索引和查詢的功能。這允許應用程式使用那種與文件資料庫應當使用的非常類似的資料模型。
從 9.3 版本開始的 PostgreSQL 【8】,從 5.7 版本開始的 MySQL 以及從版本 10.5 開始的 IBM DB2【30】也對 JSON 文件提供了類似的支援級別。鑑於用在 Web APIs 的 JSON 流行趨勢,其他關係資料庫很可能會跟隨他們的腳步並新增 JSON 支援。
在文件資料庫中,RethinkDB 在其查詢語言中支援類似關係的連線,一些 MongoDB 驅動程式可以自動解析資料庫引用(有效地執行客戶端連線,儘管這可能比在資料庫中執行的連線慢,需要額外的網路往返,並且最佳化更少)。
隨著時間的推移,關係資料庫和文件資料庫似乎變得越來越相似,這是一件好事:資料模型相互補充 [^v],如果一個數據庫能夠處理類似文件的資料,並能夠對其執行關係查詢,那麼應用程式就可以使用最符合其需求的功能組合。
關係模型和文件模型的混合是未來資料庫一條很好的路線。
[^v]: Codd 對關係模型【1】的原始描述實際上允許在關係模式中與 JSON 文件非常相似。他稱之為 非簡單域(nonsimple domains)。這個想法是,一行中的值不一定是一個像數字或字串一樣的原始資料型別,也可以是一個巢狀的關係(表),因此可以把一個任意巢狀的樹結構作為一個值,這很像 30 年後新增到 SQL 中的 JSON 或 XML 支援。
資料查詢語言
當引入關係模型時,關係模型包含了一種查詢資料的新方法:SQL 是一種 宣告式 查詢語言,而 IMS 和 CODASYL 使用 命令式 程式碼來查詢資料庫。那是什麼意思?
許多常用的程式語言是命令式的。例如,給定一個動物物種的列表,返回列表中的鯊魚可以這樣寫:
function getSharks() {
var sharks = [];
for (var i = 0; i < animals.length; i++) {
if (animals[i].family === "Sharks") {
sharks.push(animals[i]);
}
}
return sharks;
}在關係代數中: $$ sharks = σ_{family = "sharks"}(animals) $$ σ(希臘字母西格瑪)是選擇運算子,只返回符合條件的動物,family="shark"。
定義 SQL 時,它緊密地遵循關係代數的結構:
SELECT * FROM animals WHERE family ='Sharks';命令式語言告訴計算機以特定順序執行某些操作。可以想象一下,逐行地遍歷程式碼,評估條件,更新變數,並決定是否再迴圈一遍。
在宣告式查詢語言(如 SQL 或關係代數)中,你只需指定所需資料的模式 - 結果必須符合哪些條件,以及如何將資料轉換(例如,排序,分組和集合) - 但不是如何實現這一目標。資料庫系統的查詢最佳化器決定使用哪些索引和哪些連線方法,以及以何種順序執行查詢的各個部分。
宣告式查詢語言是迷人的,因為它通常比命令式 API 更加簡潔和容易。但更重要的是,它還隱藏了資料庫引擎的實現細節,這使得資料庫系統可以在無需對查詢做任何更改的情況下進行效能提升。
例如,在本節開頭所示的命令程式碼中,動物列表以特定順序出現。如果資料庫想要在後臺回收未使用的磁碟空間,則可能需要移動記錄,這會改變動物出現的順序。資料庫能否安全地執行,而不會中斷查詢?
SQL 示例不確保任何特定的順序,因此不在意順序是否改變。但是如果查詢用命令式的程式碼來寫的話,那麼資料庫就永遠不可能確定程式碼是否依賴於排序。SQL 相當有限的功能性為資料庫提供了更多自動最佳化的空間。
最後,宣告式語言往往適合並行執行。現在,CPU 的速度透過核心(core)的增加變得更快,而不是以比以前更高的時鐘速度執行【31】。命令程式碼很難在多個核心和多個機器之間並行化,因為它指定了指令必須以特定順序執行。宣告式語言更具有並行執行的潛力,因為它們僅指定結果的模式,而不指定用於確定結果的演算法。在適當情況下,資料庫可以自由使用查詢語言的並行實現【32】。
Web 上的宣告式查詢
宣告式查詢語言的優勢不僅限於資料庫。為了說明這一點,讓我們在一個完全不同的環境中比較宣告式和命令式方法:一個 Web 瀏覽器。
假設你有一個關於海洋動物的網站。使用者當前正在檢視鯊魚頁面,因此你將當前所選的導航專案 “鯊魚” 標記為當前選中專案。
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li><p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>現在想讓當前所選頁面的標題具有一個藍色的背景,以便在視覺上突出顯示。使用 CSS 實現起來非常簡單:
li.selected > p {
background-color: blue;
}這裡的 CSS 選擇器 li.selected > p 聲明瞭我們想要應用藍色樣式的元素的模式:即其直接父元素是具有 CSS 類 selected 的 <li> 元素的所有 <p> 元素。示例中的元素 <p>Sharks</p> 匹配此模式,但 <p>Whales</p> 不匹配,因為其 <li> 父元素缺少 class="selected"。
如果使用 XSL 而不是 CSS,你可以做類似的事情:
<xsl:template match="li[@class='selected']/p">
<fo:block background-color="blue">
<xsl:apply-templates/>
</fo:block>
</xsl:template>這裡的 XPath 表示式 li[@class='selected']/p 相當於上例中的 CSS 選擇器 li.selected > p。CSS 和 XSL 的共同之處在於,它們都是用於指定文件樣式的宣告式語言。
想象一下,必須使用命令式方法的情況會是如何。在 Javascript 中,使用 文件物件模型(DOM) API,其結果可能如下所示:
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}這段 JavaScript 程式碼命令式地將元素設定為藍色背景,但是程式碼看起來很糟糕。不僅比 CSS 和 XSL 等價物更長,更難理解,而且還有一些嚴重的問題:
如果選定的類被移除(例如,因為使用者點選了不同的頁面),即使程式碼重新執行,藍色背景也不會被移除 - 因此該專案將保持突出顯示,直到整個頁面被重新載入。使用 CSS,瀏覽器會自動檢測
li.selected > p規則何時不再適用,並在選定的類被移除後立即移除藍色背景。如果你想要利用新的 API(例如
document.getElementsByClassName("selected")甚至document.evaluate())來提高效能,則必須重寫程式碼。另一方面,瀏覽器供應商可以在不破壞相容性的情況下提高 CSS 和 XPath 的效能。
在 Web 瀏覽器中,使用宣告式 CSS 樣式比使用 JavaScript 命令式地操作樣式要好得多。類似地,在資料庫中,使用像 SQL 這樣的宣告式查詢語言比使用命令式查詢 API 要好得多 [^vi]。
[^vi]: IMS 和 CODASYL 都使用命令式 API。應用程式通常使用 COBOL 程式碼遍歷資料庫中的記錄,一次一條記錄【2,16】。
MapReduce查詢
MapReduce 是一個由 Google 推廣的程式設計模型,用於在多臺機器上批次處理大規模的資料【33】。一些 NoSQL 資料儲存(包括 MongoDB 和 CouchDB)支援有限形式的 MapReduce,作為在多個文件中執行只讀查詢的機制。
關於 MapReduce 更詳細的介紹在 第十章。現在我們只簡要討論一下 MongoDB 使用的模型。
MapReduce 既不是一個宣告式的查詢語言,也不是一個完全命令式的查詢 API,而是處於兩者之間:查詢的邏輯用程式碼片段來表示,這些程式碼片段會被處理框架重複性呼叫。它基於 map(也稱為 collect)和 reduce(也稱為 fold 或 inject)函式,兩個函式存在於許多函數語言程式設計語言中。
最好舉例來解釋 MapReduce 模型。假設你是一名海洋生物學家,每當你看到海洋中的動物時,你都會在資料庫中新增一條觀察記錄。現在你想生成一個報告,說明你每月看到多少鯊魚。
在 PostgreSQL 中,你可以像這樣表述這個查詢:
SELECT
date_trunc('month', observation_timestamp) AS observation_month,
sum(num_animals) AS total_animals
FROM observations
WHERE family = 'Sharks'
GROUP BY observation_month;date_trunc('month',timestamp) 函式用於確定包含 timestamp 的日曆月份,並返回代表該月份開始的另一個時間戳。換句話說,它將時間戳舍入成最近的月份。
這個查詢首先過濾觀察記錄,以只顯示鯊魚家族的物種,然後根據它們發生的日曆月份對觀察記錄果進行分組,最後將在該月的所有觀察記錄中看到的動物數目加起來。
同樣的查詢用 MongoDB 的 MapReduce 功能可以按如下來表述:
db.observations.mapReduce(function map() {
var year = this.observationTimestamp.getFullYear();
var month = this.observationTimestamp.getMonth() + 1;
emit(year + "-" + month, this.numAnimals);
},
function reduce(key, values) {
return Array.sum(values);
},
{
query: {
family: "Sharks"
},
out: "monthlySharkReport"
});- 可以宣告式地指定一個只考慮鯊魚種類的過濾器(這是 MongoDB 特定的 MapReduce 擴充套件)。
- 每個匹配查詢的文件都會呼叫一次 JavaScript 函式
map,將this設定為文件物件。 map函式發出一個鍵(包括年份和月份的字串,如"2013-12"或"2014-1")和一個值(該觀察記錄中的動物數量)。map發出的鍵值對按鍵來分組。對於具有相同鍵(即,相同的月份和年份)的所有鍵值對,呼叫一次reduce函式。reduce函式將特定月份內所有觀測記錄中的動物數量相加。- 將最終的輸出寫入到
monthlySharkReport集合中。
例如,假設 observations 集合包含這兩個文件:
{
observationTimestamp: Date.parse( "Mon, 25 Dec 1995 12:34:56 GMT"),
family: "Sharks",
species: "Carcharodon carcharias",
numAnimals: 3
}
{
observationTimestamp: Date.parse("Tue, 12 Dec 1995 16:17:18 GMT"),
family: "Sharks",
species: "Carcharias taurus",
numAnimals: 4
}對每個文件都會呼叫一次 map 函式,結果將是 emit("1995-12",3) 和 emit("1995-12",4)。隨後,以 reduce("1995-12",[3,4]) 呼叫 reduce 函式,將返回 7。
map 和 reduce 函式在功能上有所限制:它們必須是 純 函式,這意味著它們只使用傳遞給它們的資料作為輸入,它們不能執行額外的資料庫查詢,也不能有任何副作用。這些限制允許資料庫以任何順序執行任何功能,並在失敗時重新執行它們。然而,map 和 reduce 函式仍然是強大的:它們可以解析字串,呼叫庫函式,執行計算等等。
MapReduce 是一個相當底層的程式設計模型,用於計算機叢集上的分散式執行。像 SQL 這樣的更高階的查詢語言可以用一系列的 MapReduce 操作來實現(見 第十章),但是也有很多不使用 MapReduce 的分散式 SQL 實現。請注意,SQL 中沒有任何內容限制它在單個機器上執行,而 MapReduce 在分散式查詢執行上沒有壟斷權。
能夠在查詢中使用 JavaScript 程式碼是高階查詢的一個重要特性,但這不限於 MapReduce,一些 SQL 資料庫也可以用 JavaScript 函式進行擴充套件【34】。
MapReduce 的一個可用性問題是,必須編寫兩個密切合作的 JavaScript 函式,這通常比編寫單個查詢更困難。此外,宣告式查詢語言為查詢最佳化器提供了更多機會來提高查詢的效能。基於這些原因,MongoDB 2.2 添加了一種叫做 聚合管道 的宣告式查詢語言的支援【9】。用這種語言表述鯊魚計數查詢如下所示:
db.observations.aggregate([
{ $match: { family: "Sharks" } },
{ $group: {
_id: {
year: { $year: "$observationTimestamp" },
month: { $month: "$observationTimestamp" }
},
totalAnimals: { $sum: "$numAnimals" } }}
]);聚合管道語言的表現力與(前述 PostgreSQL 例子的)SQL 子集相當,但是它使用基於 JSON 的語法而不是 SQL 那種接近英文句式的語法;這種差異也許只是口味問題。這個故事的寓意是:NoSQL 系統可能會意外發現自己只是重新發明了一套經過喬裝改扮的 SQL。
圖資料模型
如我們之前所見,多對多關係是不同資料模型之間具有區別性的重要特徵。如果你的應用程式大多數的關係是一對多關係(樹狀結構化資料),或者大多數記錄之間不存在關係,那麼使用文件模型是合適的。
但是,要是多對多關係在你的資料中很常見呢?關係模型可以處理多對多關係的簡單情況,但是隨著資料之間的連線變得更加複雜,將資料建模為圖形顯得更加自然。
一個圖由兩種物件組成:頂點(vertices,也稱為 節點,即 nodes,或 實體,即 entities),和 邊(edges,也稱為 關係,即 relationships,或 弧,即 arcs)。多種資料可以被建模為一個圖形。典型的例子包括:
社交圖譜
頂點是人,邊指示哪些人彼此認識。
網路圖譜
頂點是網頁,邊緣表示指向其他頁面的 HTML 連結。
公路或鐵路網路
頂點是交叉路口,邊線代表它們之間的道路或鐵路線。
可以將那些眾所周知的演算法運用到這些圖上:例如,汽車導航系統搜尋道路網路中兩點之間的最短路徑,PageRank 可以用在網路圖上來確定網頁的流行程度,從而確定該網頁在搜尋結果中的排名。
在剛剛給出的例子中,圖中的所有頂點代表了相同型別的事物(人、網頁或交叉路口)。不過,圖並不侷限於這樣的同類資料:同樣強大地是,圖提供了一種一致的方式,用來在單個數據儲存中儲存完全不同型別的物件。例如,Facebook 維護一個包含許多不同型別的頂點和邊的單個圖:頂點表示人,地點,事件,簽到和使用者的評論;邊緣表示哪些人是彼此的朋友,哪個簽到發生在何處,誰評論了哪條訊息,誰參與了哪個事件,等等【35】。
在本節中,我們將使用 圖 2-5 所示的示例。它可以從社交網路或系譜資料庫中獲得:它顯示了兩個人,來自愛達荷州的 Lucy 和來自法國 Beaune 的 Alain。他們已婚,住在倫敦。
{kind=link}
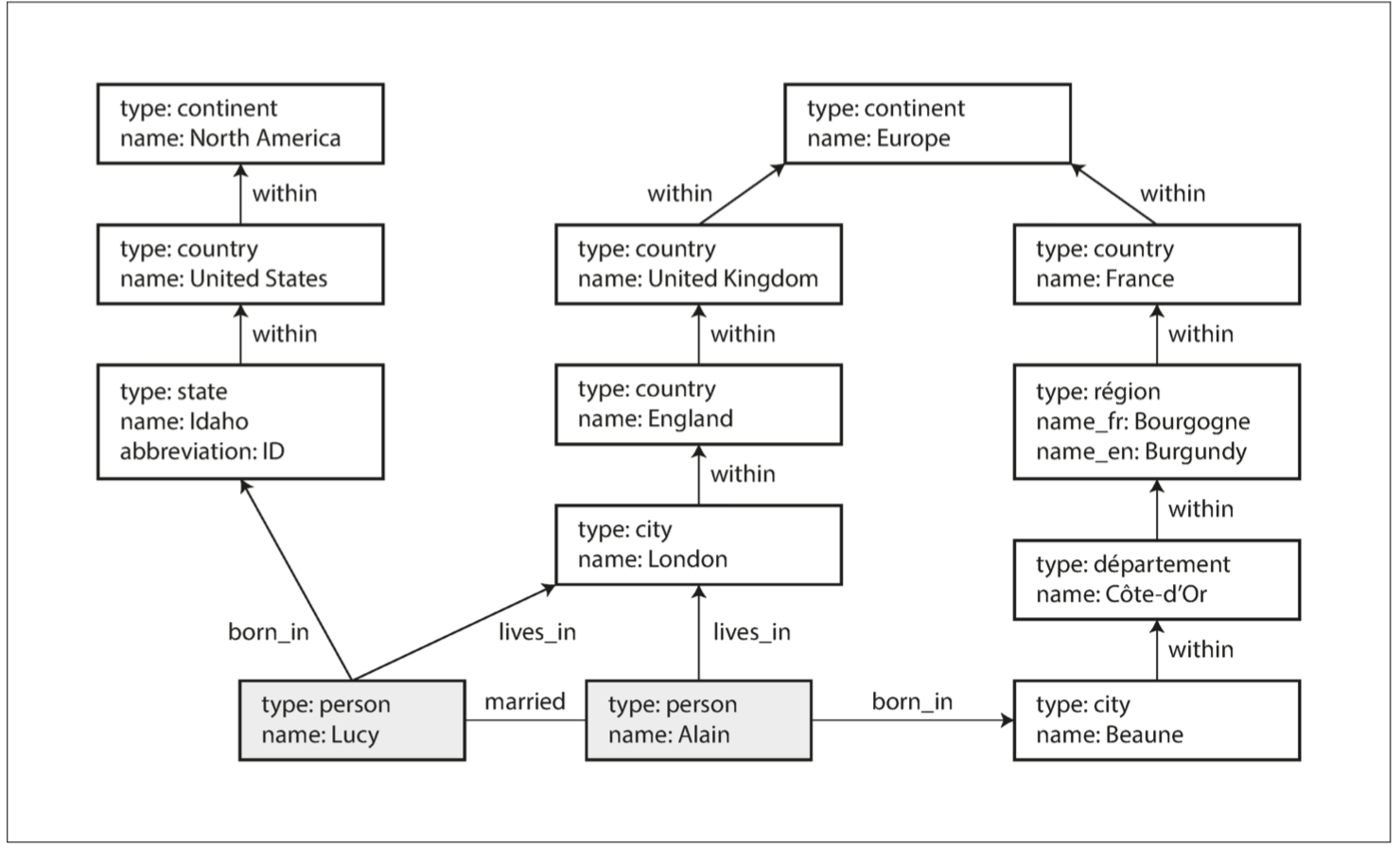
圖 2-5 圖資料結構示例(框代表頂點,箭頭代表邊)
有幾種不同但相關的方法用來構建和查詢圖表中的資料。在本節中,我們將討論屬性圖模型(由 Neo4j,Titan 和 InfiniteGraph 實現)和三元組儲存(triple-store)模型(由 Datomic,AllegroGraph 等實現)。我們將檢視圖的三種宣告式查詢語言:Cypher,SPARQL 和 Datalog。除此之外,還有像 Gremlin 【36】這樣的圖形查詢語言和像 Pregel 這樣的圖形處理框架(見 第十章)。
屬性圖
在屬性圖模型中,每個頂點(vertex)包括:
- 唯一的識別符號
- 一組出邊(outgoing edges)
- 一組入邊(ingoing edges)
- 一組屬性(鍵值對)
每條邊(edge)包括:
- 唯一識別符號
- 邊的起點(尾部頂點,即 tail vertex)
- 邊的終點(頭部頂點,即 head vertex)
- 描述兩個頂點之間關係型別的標籤
- 一組屬性(鍵值對)
可以將圖儲存看作由兩個關係表組成:一個儲存頂點,另一個儲存邊,如 例 2-2 所示(該模式使用 PostgreSQL JSON 資料型別來儲存每個頂點或每條邊的屬性)。頭部和尾部頂點用來儲存每條邊;如果你想要一組頂點的輸入或輸出邊,你可以分別透過 head_vertex 或 tail_vertex 來查詢 edges 表。
例 2-2 使用關係模式來表示屬性圖
CREATE TABLE vertices (
vertex_id INTEGER PRIMARY KEY,
properties JSON
);
CREATE TABLE edges (
edge_id INTEGER PRIMARY KEY,
tail_vertex INTEGER REFERENCES vertices (vertex_id),
head_vertex INTEGER REFERENCES vertices (vertex_id),
label TEXT,
properties JSON
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);關於這個模型的一些重要方面是:
- 任何頂點都可以有一條邊連線到任何其他頂點。沒有模式限制哪種事物可不可以關聯。
- 給定任何頂點,可以高效地找到它的入邊和出邊,從而遍歷圖,即沿著一系列頂點的路徑前後移動(這就是為什麼 例 2-2 在
tail_vertex和head_vertex列上都有索引的原因)。 - 透過對不同型別的關係使用不同的標籤,可以在一個圖中儲存幾種不同的資訊,同時仍然保持一個清晰的資料模型。
這些特性為資料建模提供了很大的靈活性,如 圖 2-5 所示。圖中顯示了一些傳統關係模式難以表達的事情,例如不同國家的不同地區結構(法國有省和大區,美國有縣和州),國中國的怪事(先忽略主權國家和民族錯綜複雜的爛攤子),不同的資料粒度(Lucy 現在的住所記錄具體到城市,而她的出生地點只是在一個州的級別)。
你可以想象該圖還能延伸出許多關於 Lucy 和 Alain 的事實,或其他人的其他更多的事實。例如,你可以用它來表示食物過敏(為每個過敏源增加一個頂點,並增加人與過敏源之間的一條邊來指示一種過敏情況),並連結到過敏源,每個過敏源具有一組頂點用來顯示哪些食物含有哪些物質。然後,你可以寫一個查詢,找出每個人吃什麼是安全的。圖在可演化性方面是富有優勢的:當你嚮應用程式新增功能時,可以輕鬆擴充套件圖以適應程式資料結構的變化。
Cypher 查詢語言
Cypher 是屬性圖的宣告式查詢語言,為 Neo4j 圖形資料庫而發明【37】(它是以電影 “駭客帝國” 中的一個角色來命名的,而與密碼學中的加密演算法無關【38】)。
例 2-3 顯示了將 圖 2-5 的左邊部分插入圖形資料庫的 Cypher 查詢。可以類似地新增圖的其餘部分,為了便於閱讀而省略。每個頂點都有一個像 USA 或 Idaho 這樣的符號名稱,查詢的其他部分可以使用這些名稱在頂點之間建立邊,使用箭頭符號:(Idaho) - [:WITHIN] ->(USA) 建立一條標記為 WITHIN 的邊,Idaho 為尾節點,USA 為頭節點。
例 2-3 將圖 2-5 中的資料子集表示為 Cypher 查詢
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)當 圖 2-5 的所有頂點和邊被新增到資料庫後,讓我們提些有趣的問題:例如,找到所有從美國移民到歐洲的人的名字。更確切地說,這裡我們想要找到符合下麵條件的所有頂點,並且返回這些頂點的 name 屬性:該頂點擁有一條連到美國任一位置的 BORN_IN 邊,和一條連到歐洲的任一位置的 LIVING_IN 邊。
例 2-4 展示瞭如何在 Cypher 中表達這個查詢。在 MATCH 子句中使用相同的箭頭符號來查詢圖中的模式:(person) -[:BORN_IN]-> () 可以匹配 BORN_IN 邊的任意兩個頂點。該邊的尾節點被綁定了變數 person,頭節點則未被繫結。
例 2-4 查詢所有從美國移民到歐洲的人的 Cypher 查詢:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name查詢按如下來解讀:
找到滿足以下兩個條件的所有頂點(稱之為 person 頂點):
person頂點擁有一條到某個頂點的BORN_IN出邊。從那個頂點開始,沿著一系列WITHIN出邊最終到達一個型別為Location,name屬性為United States的頂點。
person頂點還擁有一條LIVES_IN出邊。沿著這條邊,可以透過一系列WITHIN出邊最終到達一個型別為Location,name屬性為Europe的頂點。對於這樣的
Person頂點,返回其name屬性。
執行這條查詢可能會有幾種可行的查詢路徑。這裡給出的描述建議首先掃描資料庫中的所有人,檢查每個人的出生地和居住地,然後只返回符合條件的那些人。
等價地,也可以從兩個 Location 頂點開始反向地查詢。假如 name 屬性上有索引,則可以高效地找到代表美國和歐洲的兩個頂點。然後,沿著所有 WITHIN 入邊,可以繼續查找出所有在美國和歐洲的位置(州,地區,城市等)。最後,查找出那些可以由 BORN_IN 或 LIVES_IN 入邊到那些位置頂點的人。
通常對於宣告式查詢語言來說,在編寫查詢語句時,不需要指定執行細節:查詢最佳化程式會自動選擇預測效率最高的策略,因此你可以專注於編寫應用程式的其他部分。
SQL 中的圖查詢
例 2-2 指出,可以在關係資料庫中表示圖資料。但是,如果圖資料已經以關係結構儲存,我們是否也可以使用 SQL 查詢它?
答案是肯定的,但有些困難。在關係資料庫中,你通常會事先知道在查詢中需要哪些連線。在圖查詢中,你可能需要在找到待查詢的頂點之前,遍歷可變數量的邊。也就是說,連線的數量事先並不確定。
在我們的例子中,這發生在 Cypher 查詢中的 () -[:WITHIN*0..]-> () 規則中。一個人的 LIVES_IN 邊可以指向任何型別的位置:街道、城市、地區、國家等。一個城市可以在(WITHIN)一個地區內,一個地區可以在(WITHIN)在一個州內,一個州可以在(WITHIN)一個國家內,等等。LIVES_IN 邊可以直接指向正在查詢的位置,或者一個在位置層次結構中隔了數層的位置。
在 Cypher 中,用 WITHIN*0.. 非常簡潔地表述了上述事實:“沿著 WITHIN 邊,零次或多次”。它很像正則表示式中的 * 運算子。
自 SQL:1999,查詢可變長度遍歷路徑的思想可以使用稱為 遞迴公用表表達式(WITH RECURSIVE 語法)的東西來表示。例 2-5 顯示了同樣的查詢 - 查詢從美國移民到歐洲的人的姓名 - 在 SQL 使用這種技術(PostgreSQL、IBM DB2、Oracle 和 SQL Server 均支援)來表述。但是,與 Cypher 相比,其語法非常笨拙。
例 2-5 與示例 2-4 同樣的查詢,在 SQL 中使用遞迴公用表表達式表示
WITH RECURSIVE
-- in_usa 包含所有的美國境內的位置 ID
in_usa(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'United States'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'within'
),
-- in_europe 包含所有的歐洲境內的位置 ID
in_europe(vertex_id) AS (
SELECT vertex_id FROM vertices WHERE properties ->> 'name' = 'Europe'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within' ),
-- born_in_usa 包含了所有型別為 Person,且出生在美國的頂點
born_in_usa(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in' ),
-- lives_in_europe 包含了所有型別為 Person,且居住在歐洲的頂點。
lives_in_europe(vertex_id) AS (
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in')
SELECT vertices.properties ->> 'name'
FROM vertices
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;- 首先,查詢
name屬性為United States的頂點,將其作為in_usa頂點的集合的第一個元素。 - 從
in_usa集合的頂點出發,沿著所有的with_in入邊,將其尾頂點加入同一集合,不斷遞迴直到所有with_in入邊都被訪問完畢。 - 同理,從
name屬性為Europe的頂點出發,建立in_europe頂點的集合。 - 對於
in_usa集合中的每個頂點,根據born_in入邊來查找出生在美國某個地方的人。 - 同樣,對於
in_europe集合中的每個頂點,根據lives_in入邊來查詢居住在歐洲的人。 - 最後,把在美國出生的人的集合與在歐洲居住的人的集合相交。
同一個查詢,用某一個查詢語言可以寫成 4 行,而用另一個查詢語言需要 29 行,這恰恰說明了不同的資料模型是為不同的應用場景而設計的。選擇適合應用程式的資料模型非常重要。
三元組儲存和 SPARQL
三元組儲存模式大體上與屬性圖模型相同,用不同的詞來描述相同的想法。不過仍然值得討論,因為三元組儲存有很多現成的工具和語言,這些工具和語言對於構建應用程式的工具箱可能是寶貴的補充。
在三元組儲存中,所有資訊都以非常簡單的三部分表示形式儲存(主語,謂語,賓語)。例如,三元組 (吉姆, 喜歡, 香蕉) 中,吉姆 是主語,喜歡 是謂語(動詞),香蕉 是物件。
三元組的主語相當於圖中的一個頂點。而賓語是下面兩者之一:
- 原始資料型別中的值,例如字串或數字。在這種情況下,三元組的謂語和賓語相當於主語頂點上的屬性的鍵和值。例如,
(lucy, age, 33)就像屬性{“age”:33}的頂點 lucy。 - 圖中的另一個頂點。在這種情況下,謂語是圖中的一條邊,主語是其尾部頂點,而賓語是其頭部頂點。例如,在
(lucy, marriedTo, alain)中主語和賓語lucy和alain都是頂點,並且謂語marriedTo是連線他們的邊的標籤。
例 2-6 展示了與 例 2-3 相同的資料,以稱為 Turtle 的格式(Notation3(N3)【39】的一個子集)寫成三元組。
例 2-6 圖 2-5 中的資料子集,表示為 Turtle 三元組
@prefix : <urn:example:>.
_:lucy a :Person.
_:lucy :name "Lucy".
_:lucy :bornIn _:idaho.
_:idaho a :Location.
_:idaho :name "Idaho".
_:idaho :type "state".
_:idaho :within _:usa.
_:usa a :Location
_:usa :name "United States"
_:usa :type "country".
_:usa :within _:namerica.
_:namerica a :Location
_:namerica :name "North America"
_:namerica :type :"continent"在這個例子中,圖的頂點被寫為:_:someName。這個名字並不意味著這個檔案以外的任何東西。它的存在只是幫助我們明確哪些三元組引用了同一頂點。當謂語表示邊時,該賓語是一個頂點,如 _:idaho :within _:usa.。當謂語是一個屬性時,該賓語是一個字串,如 _:usa :name"United States"
一遍又一遍地重複相同的主語看起來相當重複,但幸運的是,可以使用分號來說明關於同一主語的多個事情。這使得 Turtle 格式相當不錯,可讀性強:請參閱 例 2-7。
例 2-7 一種相對例 2-6 寫入資料的更為簡潔的方法。
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa
_:usa a :Loaction; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".語義網
如果你深入瞭解關於三元組儲存的資訊,可能會陷入關於語義網的討論漩渦中。三元組儲存模型其實是完全獨立於語義網存在的,例如,Datomic【40】作為一種三元組儲存資料庫 [^vii],從未被用於語義網中。但是,由於在很多人眼中這兩者緊密相連,我們應該簡要地討論一下。
[^vii]: 從技術上講,Datomic 使用的是五元組而不是三元組,兩個額外的欄位是用於版本控制的元資料
從本質上講,語義網是一個簡單且合理的想法:網站已經將資訊釋出為文字和圖片供人類閱讀,為什麼不將資訊作為機器可讀的資料也釋出給計算機呢?(基於三元組模型的)資源描述框架(RDF)【41】,被用作不同網站以統一的格式釋出資料的一種機制,允許來自不同網站的資料自動合併成 一個數據網路 —— 成為一種網際網路範圍內的 “通用語義網資料庫”。
不幸的是,語義網在二十一世紀初被過度炒作,但到目前為止沒有任何跡象表明已在實踐中應用,這使得許多人嗤之以鼻。它還飽受眼花繚亂的縮略詞、過於複雜的標準提案和狂妄自大的困擾。
然而,如果從過去的失敗中汲取教訓,語義網專案還是擁有很多優秀的成果。即使你沒有興趣在語義網上釋出 RDF 資料,三元組這種模型也是一種好的應用程式內部資料模型。
RDF 資料模型
例 2-7 中使用的 Turtle 語言是一種用於 RDF 資料的人類可讀格式。有時候,RDF 也可以以 XML 格式編寫,不過完成同樣的事情會相對囉嗦,請參閱 例 2-8。Turtle/N3 是更可取的,因為它更容易閱讀,像 Apache Jena 【42】這樣的工具可以根據需要在不同的 RDF 格式之間進行自動轉換。
例 2-8 用 RDF/XML 語法表示例 2-7 的資料
<rdf:RDF xmlns="urn:example:"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Location rdf:nodeID="idaho">
<name>Idaho</name>
<type>state</type>
<within>
<Location rdf:nodeID="usa">
<name>United States</name>
<type>country</type>
<within>
<Location rdf:nodeID="namerica">
<name>North America</name>
<type>continent</type>
</Location>
</within>
</Location>
</within>
</Location>
<Person rdf:nodeID="lucy">
<name>Lucy</name>
<bornIn rdf:nodeID="idaho"/>
</Person>
</rdf:RDF>RDF 有一些奇怪之處,因為它是為了在網際網路上交換資料而設計的。三元組的主語,謂語和賓語通常是 URI。例如,謂語可能是一個 URI,如 <http://my-company.com/namespace#within> 或 <http://my-company.com/namespace#lives_in>,而不僅僅是 WITHIN 或 LIVES_IN。這個設計背後的原因為了讓你能夠把你的資料和其他人的資料結合起來,如果他們賦予單詞 within 或者 lives_in 不同的含義,兩者也不會衝突,因為它們的謂語實際上是 <http://other.org/foo#within> 和 <http://other.org/foo#lives_in>。
從 RDF 的角度來看,URL <http://my-company.com/namespace> 不一定需要能解析成什麼東西,它只是一個名稱空間。為避免與 http://URL 混淆,本節中的示例使用不可解析的 URI,如 urn:example:within。幸運的是,你只需在檔案頂部對這個字首做一次宣告,後續就不用再管了。
SPARQL 查詢語言
SPARQL 是一種用於三元組儲存的面向 RDF 資料模型的查詢語言【43】(它是 SPARQL 協議和 RDF 查詢語言的縮寫,發音為 “sparkle”)。SPARQL 早於 Cypher,並且由於 Cypher 的模式匹配借鑑於 SPARQL,這使得它們看起來非常相似【37】。
與之前相同的查詢 —— 查詢從美國移民到歐洲的人 —— 使用 SPARQL 比使用 Cypher 甚至更為簡潔(請參閱 例 2-9)。
例 2-9 與示例 2-4 相同的查詢,用 SPARQL 表示
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}結構非常相似。以下兩個表示式是等價的(SPARQL 中的變數以問號開頭):
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher
?person :bornIn / :within* ?location. # SPARQL因為 RDF 不區分屬性和邊,而只是將它們作為謂語,所以可以使用相同的語法來匹配屬性。在下面的表示式中,變數 usa 被繫結到任意 name 屬性為字串值 "United States" 的頂點:
(usa {name:'United States'}) # Cypher
?usa :name "United States". # SPARQLSPARQL 是一種很好的查詢語言 —— 儘管它構想的語義網從未實現,但它仍然是一種可用於應用程式內部的強大工具。
圖形資料庫與網狀模型相比較
在 “文件資料庫是否在重蹈覆轍?” 中,我們討論了 CODASYL 和關係模型如何競相解決 IMS 中的多對多關係問題。乍一看,CODASYL 的網狀模型看起來與圖模型相似。CODASYL 是否是圖形資料庫的第二個變種?
不,他們在幾個重要方面有所不同:
- 在 CODASYL 中,資料庫有一個模式,用於指定哪種記錄型別可以巢狀在其他記錄型別中。在圖形資料庫中,不存在這樣的限制:任何頂點都可以具有到其他任何頂點的邊。這為應用程式適應不斷變化的需求提供了更大的靈活性。
- 在 CODASYL 中,達到特定記錄的唯一方法是遍歷其中的一個訪問路徑。在圖形資料庫中,可以透過其唯一 ID 直接引用任何頂點,也可以使用索引來查詢具有特定值的頂點。
- 在 CODASYL 中,記錄的子專案是一個有序集合,所以資料庫必須去管理它們的次序(這會影響儲存佈局),並且應用程式在插入新記錄到資料庫時必須關注新記錄在這些集合中的位置。在圖形資料庫中,頂點和邊是無序的(只能在查詢時對結果進行排序)。
- 在 CODASYL 中,所有查詢都是命令式的,難以編寫,並且很容易因架構變化而受到破壞。在圖形資料庫中,你可以在命令式程式碼中手寫遍歷過程,但大多數圖形資料庫都支援高階宣告式查詢,如 Cypher 或 SPARQL。
基礎:Datalog
Datalog 是比 SPARQL、Cypher 更古老的語言,在 20 世紀 80 年代被學者廣泛研究【44,45,46】。它在軟體工程師中不太知名,但是它是重要的,因為它為以後的查詢語言提供了基礎。
實踐中,Datalog 在有限的幾個資料系統中使用:例如,它是 Datomic 【40】的查詢語言,Cascalog 【47】是一種用於查詢 Hadoop 大資料集的 Datalog 實現 [^viii]。
[^viii]: Datomic 和 Cascalog 使用 Datalog 的 Clojure S 表示式語法。在下面的例子中使用了一個更容易閱讀的 Prolog 語法,但兩者沒有任何功能差異。
Datalog 的資料模型類似於三元組模式,但進行了一點泛化。把三元組寫成 謂語(主語,賓語),而不是寫三元語(主語,謂語,賓語)。例 2-10 顯示瞭如何用 Datalog 寫入我們的例子中的資料。
例 2-10 用 Datalog 來表示圖 2-5 中的資料子集
name(namerica, 'North America').
type(namerica, continent).
name(usa, 'United States').
type(usa, country).
within(usa, namerica).
name(idaho, 'Idaho').
type(idaho, state).
within(idaho, usa).
name(lucy, 'Lucy').
born_in(lucy, idaho).既然已經定義了資料,我們可以像之前一樣編寫相同的查詢,如 例 2-11 所示。它看起來與 Cypher 或 SPARQL 的語法差異較大,但請不要抗拒它。Datalog 是 Prolog 的一個子集,如果你是電腦科學專業的學生,可能已經見過 Prolog。
例 2-11 與示例 2-4 相同的查詢,用 Datalog 表示
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe'). /* Who = 'Lucy'. */Cypher 和 SPARQL 使用 SELECT 立即跳轉,但是 Datalog 一次只進行一小步。我們定義 規則,以將新謂語告訴資料庫:在這裡,我們定義了兩個新的謂語,within_recursive 和 migrated。這些謂語不是儲存在資料庫中的三元組中,而是從資料或其他規則派生而來的。規則可以引用其他規則,就像函式可以呼叫其他函式或者遞迴地呼叫自己一樣。像這樣,複雜的查詢可以藉由小的磚瓦構建起來。
在規則中,以大寫字母開頭的單詞是變數,謂語則用 Cypher 和 SPARQL 的方式一樣來匹配。例如,name(Location, Name) 透過變數繫結 Location = namerica 和 Name ='North America' 可以匹配三元組 name(namerica, 'North America')。
要是系統可以在 :- 運算子的右側找到與所有謂語的一個匹配,就運用該規則。當規則運用時,就好像透過 :- 的左側將其新增到資料庫(將變數替換成它們匹配的值)。
因此,一種可能的應用規則的方式是:
- 資料庫存在
name (namerica, 'North America'),故運用規則 1。它生成within_recursive (namerica, 'North America')。 - 資料庫存在
within (usa, namerica),在上一步驟中生成within_recursive (namerica, 'North America'),故運用規則 2。它會產生within_recursive (usa, 'North America')。 - 資料庫存在
within (idaho, usa),在上一步生成within_recursive (usa, 'North America'),故運用規則 2。它產生within_recursive (idaho, 'North America')。
透過重複應用規則 1 和 2,within_recursive 謂語可以告訴我們在資料庫中包含北美(或任何其他位置名稱)的所有位置。這個過程如 圖 2-6 所示。
{kind=link}
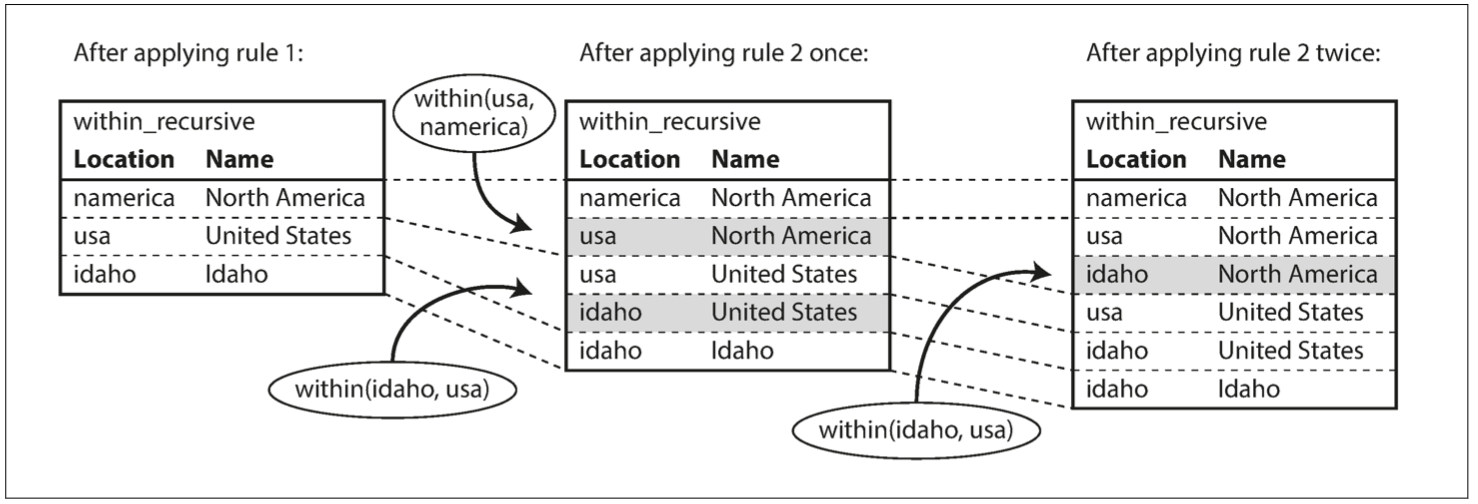
圖 2-6 使用示例 2-11 中的 Datalog 規則來確定愛達荷州在北美。
現在規則 3 可以找到出生在某個地方 BornIn 的人,並住在某個地方 LivingIn。透過查詢 BornIn ='United States' 和 LivingIn ='Europe',並將此人作為變數 Who,讓 Datalog 系統找出變數 Who 會出現哪些值。因此,最後得到了與早先的 Cypher 和 SPARQL 查詢相同的答案。
相對於本章討論的其他查詢語言,我們需要採取不同的思維方式來思考 Datalog 方法,但這是一種非常強大的方法,因為規則可以在不同的查詢中進行組合和重用。雖然對於簡單的一次性查詢,顯得不太方便,但是它可以更好地處理資料很複雜的情況。
本章小結
資料模型是一個巨大的課題,在本章中,我們快速瀏覽了各種不同的模型。我們沒有足夠的篇幅來詳述每個模型的細節,但是希望這個概述足以激起你的興趣,以更多地瞭解最適合你的應用需求的模型。
在歷史上,資料最開始被表示為一棵大樹(層次資料模型),但是這不利於表示多對多的關係,所以發明了關係模型來解決這個問題。最近,開發人員發現一些應用程式也不適合採用關係模型。新的非關係型 “NoSQL” 資料儲存分化為兩個主要方向:
- 文件資料庫 主要關注自我包含的資料文件,而且文件之間的關係非常稀少。
- 圖形資料庫 用於相反的場景:任意事物之間都可能存在潛在的關聯。
這三種模型(文件,關係和圖形)在今天都被廣泛使用,並且在各自的領域都發揮很好。一個模型可以用另一個模型來模擬 —— 例如,圖資料可以在關係資料庫中表示 —— 但結果往往是糟糕的。這就是為什麼我們有著針對不同目的的不同系統,而不是一個單一的萬能解決方案。
文件資料庫和圖資料庫有一個共同點,那就是它們通常不會將儲存的資料強制約束為特定模式,這可以使應用程式更容易適應不斷變化的需求。但是應用程式很可能仍會假定資料具有一定的結構;區別僅在於模式是明確的(寫入時強制)還是隱含的(讀取時處理)。
每個資料模型都具有各自的查詢語言或框架,我們討論了幾個例子:SQL,MapReduce,MongoDB 的聚合管道,Cypher,SPARQL 和 Datalog。我們也談到了 CSS 和 XSL/XPath,它們不是資料庫查詢語言,而包含有趣的相似之處。
雖然我們已經覆蓋了很多層面,但仍然有許多資料模型沒有提到。舉幾個簡單的例子:
- 使用基因組資料的研究人員通常需要執行 序列相似性搜尋,這意味著需要一個很長的字串(代表一個 DNA 序列),並在一個擁有類似但不完全相同的字串的大型資料庫中尋找匹配。這裡所描述的資料庫都不能處理這種用法,這就是為什麼研究人員編寫了像 GenBank 這樣的專門的基因組資料庫軟體的原因【48】。
- 粒子物理學家數十年來一直在進行大資料型別的大規模資料分析,像大型強子對撞機(LHC)這樣的專案現在會處理數百 PB 的資料!在這樣的規模下,需要定製解決方案來阻止硬體成本的失控【49】。
- 全文搜尋 可以說是一種經常與資料庫一起使用的資料模型。資訊檢索是一個很大的專業課題,我們不會在本書中詳細介紹,但是我們將在第三章和第三部分中介紹搜尋索引。
讓我們暫時將其放在一邊。在 下一章 中,我們將討論在 實現 本章描述的資料模型時會遇到的一些權衡。
參考文獻
- Edgar F. Codd: “A Relational Model of Data for Large Shared Data Banks,” Communications of the ACM, volume 13, number 6, pages 377–387, June 1970. doi:10.1145/362384.362685
- Michael Stonebraker and Joseph M. Hellerstein: “What Goes Around Comes Around,” in Readings in Database Systems, 4th edition, MIT Press, pages 2–41, 2005. ISBN: 978-0-262-69314-1
- Pramod J. Sadalage and Martin Fowler: NoSQL Distilled. Addison-Wesley, August 2012. ISBN: 978-0-321-82662-6
- Eric Evans: “NoSQL: What's in a Name?,” blog.sym-link.com, October 30, 2009.
- James Phillips: “Surprises in Our NoSQL Adoption Survey,” blog.couchbase.com, February 8, 2012.
- Michael Wagner: SQL/XML:2006 – Evaluierung der Standardkonformität ausgewählter Datenbanksysteme. Diplomica Verlag, Hamburg, 2010. ISBN: 978-3-836-64609-3
- “XML Data in SQL Server,” SQL Server 2012 documentation, technet.microsoft.com, 2013.
- “PostgreSQL 9.3.1 Documentation,” The PostgreSQL Global Development Group, 2013.
- “The MongoDB 2.4 Manual,” MongoDB, Inc., 2013.
- “RethinkDB 1.11 Documentation,” rethinkdb.com, 2013.
- “Apache CouchDB 1.6 Documentation,” docs.couchdb.org, 2014.
- Lin Qiao, Kapil Surlaker, Shirshanka Das, et al.: “On Brewing Fresh Espresso: LinkedIn’s Distributed Data Serving Platform,” at ACM International Conference on Management of Data (SIGMOD), June 2013.
- Rick Long, Mark Harrington, Robert Hain, and Geoff Nicholls: IMS Primer. IBM Redbook SG24-5352-00, IBM International Technical Support Organization, January 2000.
- Stephen D. Bartlett: “IBM’s IMS—Myths, Realities, and Opportunities,” The Clipper Group Navigator, TCG2013015LI, July 2013.
- Sarah Mei: “Why You Should Never Use MongoDB,” sarahmei.com, November 11, 2013.
- J. S. Knowles and D. M. R. Bell: “The CODASYL Model,” in Databases—Role and Structure: An Advanced Course, edited by P. M. Stocker, P. M. D. Gray, and M. P. Atkinson, pages 19–56, Cambridge University Press, 1984. ISBN: 978-0-521-25430-4
- Charles W. Bachman: “The Programmer as Navigator,” Communications of the ACM, volume 16, number 11, pages 653–658, November 1973. doi:10.1145/355611.362534
- Joseph M. Hellerstein, Michael Stonebraker, and James Hamilton: “Architecture of a Database System,” Foundations and Trends in Databases, volume 1, number 2, pages 141–259, November 2007. doi:10.1561/1900000002
- Sandeep Parikh and Kelly Stirman: “Schema Design for Time Series Data in MongoDB,” blog.mongodb.org, October 30, 2013.
- Martin Fowler: “Schemaless Data Structures,” martinfowler.com, January 7, 2013.
- Amr Awadallah: “Schema-on-Read vs. Schema-on-Write,” at Berkeley EECS RAD Lab Retreat, Santa Cruz, CA, May 2009.
- Martin Odersky: “The Trouble with Types,” at Strange Loop, September 2013.
- Conrad Irwin: “MongoDB—Confessions of a PostgreSQL Lover,” at HTML5DevConf, October 2013.
- “Percona Toolkit Documentation: pt-online-schema-change,” Percona Ireland Ltd., 2013.
- Rany Keddo, Tobias Bielohlawek, and Tobias Schmidt: “Large Hadron Migrator,” SoundCloud, 2013. Shlomi Noach: “gh-ost: GitHub's Online Schema Migration Tool for MySQL,” githubengineering.com, August 1, 2016.
- James C. Corbett, Jeffrey Dean, Michael Epstein, et al.: “Spanner: Google’s Globally-Distributed Database,” at 10th USENIX Symposium on Operating System Design and Implementation (OSDI), October 2012.
- Donald K. Burleson: “Reduce I/O with Oracle Cluster Tables,” dba-oracle.com.
- Fay Chang, Jeffrey Dean, Sanjay Ghemawat, et al.: “Bigtable: A Distributed Storage System for Structured Data,” at 7th USENIX Symposium on Operating System Design and Implementation (OSDI), November 2006.
- Bobbie J. Cochrane and Kathy A. McKnight: “DB2 JSON Capabilities, Part 1: Introduction to DB2 JSON,” IBM developerWorks, June 20, 2013.
- Herb Sutter: “The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software,” Dr. Dobb's Journal, volume 30, number 3, pages 202-210, March 2005.
- Joseph M. Hellerstein: “The Declarative Imperative: Experiences and Conjectures in Distributed Logic,” Electrical Engineering and Computer Sciences, University of California at Berkeley, Tech report UCB/EECS-2010-90, June 2010.
- Jeffrey Dean and Sanjay Ghemawat: “MapReduce: Simplified Data Processing on Large Clusters,” at 6th USENIX Symposium on Operating System Design and Implementation (OSDI), December 2004.
- Craig Kerstiens: “JavaScript in Your Postgres,” blog.heroku.com, June 5, 2013.
- Nathan Bronson, Zach Amsden, George Cabrera, et al.: “TAO: Facebook’s Distributed Data Store for the Social Graph,” at USENIX Annual Technical Conference (USENIX ATC), June 2013.
- “Apache TinkerPop3.2.3 Documentation,” tinkerpop.apache.org, October 2016.
- “The Neo4j Manual v2.0.0,” Neo Technology, 2013. Emil Eifrem: Twitter correspondence, January 3, 2014.
- David Beckett and Tim Berners-Lee: “Turtle – Terse RDF Triple Language,” W3C Team Submission, March 28, 2011.
- “Datomic Development Resources,” Metadata Partners, LLC, 2013. W3C RDF Working Group: “Resource Description Framework (RDF),” w3.org, 10 February 2004.
- “Apache Jena,” Apache Software Foundation.
- Steve Harris, Andy Seaborne, and Eric Prud'hommeaux: “SPARQL 1.1 Query Language,” W3C Recommendation, March 2013.
- Todd J. Green, Shan Shan Huang, Boon Thau Loo, and Wenchao Zhou: “Datalog and Recursive Query Processing,” Foundations and Trends in Databases, volume 5, number 2, pages 105–195, November 2013. doi:10.1561/1900000017
- Stefano Ceri, Georg Gottlob, and Letizia Tanca: “What You Always Wanted to Know About Datalog (And Never Dared to Ask),” IEEE Transactions on Knowledge and Data Engineering, volume 1, number 1, pages 146–166, March 1989. doi:10.1109/69.43410
- Serge Abiteboul, Richard Hull, and Victor Vianu: Foundations of Databases. Addison-Wesley, 1995. ISBN: 978-0-201-53771-0, available online at webdam.inria.fr/Alice
- Nathan Marz: “Cascalog," cascalog.org. Dennis A. Benson, Ilene Karsch-Mizrachi, David J. Lipman, et al.: “GenBank,” Nucleic Acids Research, volume 36, Database issue, pages D25–D30, December 2007. doi:10.1093/nar/gkm929
- Fons Rademakers: “ROOT for Big Data Analysis,” at Workshop on the Future of Big Data Management, London, UK, June 2013.
| 上一章 | 目錄 | 下一章 |
|---|---|---|
| 第一章:可靠性、可伸縮性和可維護性 | 設計資料密集型應用 | 第三章:儲存與檢索 |